| 1C |
22.09.25
✎
09:00
Здравствуйте. На БД (весом 150гб+) начали долго выполняться отчеты и проводиться некоторые операции, а также стали долго отрабатывать регламенты ("Групповое перепроведение ИПЧ", вдруг знакомо).
Проблемы тормозов совпали (?) с переведением БД из "простой" модели восстановления в "полную", с включение обрезки ЖТР MSSQL (по времени, раз в час), а также включением зеркалирования на другой, аналогичный по характеристикам, сервер (немного различается размер кластера диска с БД и ЖТР на основном и зеркальном сервере, т.к. разные диски (NVME SSD), в остальном - идентичные).
Вводные:
1. ОС Windows Server 2022
2. MS SQL 2022 Enterprise
3. Версия платформы 8.3.27.1688
4. Конфигурация 1С:УНФ 8. Управление предприятием общепита, редакция 3.0 (3.0.5.184)
Какие были попытки решения проблемы:
1. Пауза зеркалирования - не помогло
2. Отключение зеркалирования - не помогло
3. Перезапуск платформы - не помогло
4. Перезапуск платформы с очисткой сеансового кеша - не помогло
5. Отключение прочих БД, которые расположены на том же сервере и подключены к той же СУБД, с отключение регламентов с перезапуском СУБД и платформы - не помогло
6. Перезагрузка сервера полностью - не помогло
При этом, если восстановить эту БД на другом сервере (на который осуществлялось зеркалирование) - то всё ок, показательный отчет формируется за 1-1.5 минуты, при том, что на проблемном он формируется 20-25 минут %)
Финт с бекапом на проблемном, разверткой на нормальном, и обратным бекапом и разверткой на проблемном - не прокатил, результаты те же, медленно. По словам 1с-программиста, в других базах (а их рядом ещё 3) таких тормозов нет
Снова перевел проблемную БД на "простую" модель восстановления в MSSQL (считай вернулся к исходному её состоянию) - также медленно.
Рядом с боевой сбойной базой есть такая же, как типа демо, там проблемы воспроизводятся тоже - медленное выполнение отчетов и т.п.
На этой проблемной и других БД, подключенных к этому же серверу СУБД, проводится регламенты по реорганизации индексов (если фрагментация более 5%) и перестроение индекса (если фрагментация >30%) с перестроением планов запросов по этим индексам, а также обновление статистики 2 раза в день с очисткой процедурного кеша.
Параллельно, на ныне сбойный сервер (будем его называть так) также было сделано зеркалирования с зеркального сервера другой БД.
После чего в логах MSSQL появились записи вида:
There have been 60160 misaligned log IOs which required falling back to synchronous IO.
В журнале ОС соответственно: Имеется 60416 операций ввода-вывода журнала с неверным выравниванием, что привело к необходимости возврата к синхронному вводу-выводу.
Примеры сообщений выдернуты в разное время из журналов.
После чего проверил параметры дисков на этих двух серверах.
На сбойном параметры диска с БЖ и ЖТР такие:
C:\Windows\system32>fsutil fsinfo sectorinfo E:
LogicalBytesPerSector : 512
PhysicalBytesPerSectorForAtomicity : 4096
PhysicalBytesPerSectorForPerformance : 4096
FileSystemEffectivePhysicalBytesPerSectorForAtomicity : 4096
Выравнивание устройства : Выровнено (0x000)
Выравнивание разделов на устройстве : Выровнено (0x000)
Без штрафа за поиск
Очистка поддерживается
Не поддерживает DAX
Без тонкой подготовки
На нормальном такие:
C:\Windows\system32>fsutil fsinfo sectorinfo E:
LogicalBytesPerSector : 512
PhysicalBytesPerSectorForAtomicity : 512
PhysicalBytesPerSectorForPerformance : 512
FileSystemEffectivePhysicalBytesPerSectorForAtomicity : 512
Выравнивание устройства : Выровнено (0x000)
Выравнивание разделов на устройстве : Выровнено (0x000)
Без штрафа за поиск
Очистка поддерживается
Не поддерживает DAX
Без тонкой подготовки
Вот собственно и вся разница) попытался форматированием диска Е на сбойном привести размеры соответствие - не вышло, форматированием не решается. Пишут, что особенности используемых дисков.
Сейчас все зеркалирования отключены.
Также добавлю, что, судя по виндовым счетчикам производительности, большой нагрузки на дисковую подсистему нет. Утилизация дисков минимальна, лишь в редкие моменты подскакивает до больших значений.
TempDB MSSQL и ЖР 1С выведены на отдельный, от файлов БД и ЖТР, диск, более быстрый.
Нагрузка по ЦПУ и ОЗУ (MSSQL отъедает выделенную ему память) также в норме.
Уважаемое сообщество, подскажите, куда ещё можно копнуть?
Проблемы тормозов совпали (?) с переведением БД из "простой" модели восстановления в "полную", с включение обрезки ЖТР MSSQL (по времени, раз в час), а также включением зеркалирования на другой, аналогичный по характеристикам, сервер (немного различается размер кластера диска с БД и ЖТР на основном и зеркальном сервере, т.к. разные диски (NVME SSD), в остальном - идентичные).
Вводные:
1. ОС Windows Server 2022
2. MS SQL 2022 Enterprise
3. Версия платформы 8.3.27.1688
4. Конфигурация 1С:УНФ 8. Управление предприятием общепита, редакция 3.0 (3.0.5.184)
Какие были попытки решения проблемы:
1. Пауза зеркалирования - не помогло
2. Отключение зеркалирования - не помогло
3. Перезапуск платформы - не помогло
4. Перезапуск платформы с очисткой сеансового кеша - не помогло
5. Отключение прочих БД, которые расположены на том же сервере и подключены к той же СУБД, с отключение регламентов с перезапуском СУБД и платформы - не помогло
6. Перезагрузка сервера полностью - не помогло
При этом, если восстановить эту БД на другом сервере (на который осуществлялось зеркалирование) - то всё ок, показательный отчет формируется за 1-1.5 минуты, при том, что на проблемном он формируется 20-25 минут %)
Финт с бекапом на проблемном, разверткой на нормальном, и обратным бекапом и разверткой на проблемном - не прокатил, результаты те же, медленно. По словам 1с-программиста, в других базах (а их рядом ещё 3) таких тормозов нет
Снова перевел проблемную БД на "простую" модель восстановления в MSSQL (считай вернулся к исходному её состоянию) - также медленно.
Рядом с боевой сбойной базой есть такая же, как типа демо, там проблемы воспроизводятся тоже - медленное выполнение отчетов и т.п.
На этой проблемной и других БД, подключенных к этому же серверу СУБД, проводится регламенты по реорганизации индексов (если фрагментация более 5%) и перестроение индекса (если фрагментация >30%) с перестроением планов запросов по этим индексам, а также обновление статистики 2 раза в день с очисткой процедурного кеша.
Параллельно, на ныне сбойный сервер (будем его называть так) также было сделано зеркалирования с зеркального сервера другой БД.
После чего в логах MSSQL появились записи вида:
There have been 60160 misaligned log IOs which required falling back to synchronous IO.
В журнале ОС соответственно: Имеется 60416 операций ввода-вывода журнала с неверным выравниванием, что привело к необходимости возврата к синхронному вводу-выводу.
Примеры сообщений выдернуты в разное время из журналов.
После чего проверил параметры дисков на этих двух серверах.
На сбойном параметры диска с БЖ и ЖТР такие:
C:\Windows\system32>fsutil fsinfo sectorinfo E:
LogicalBytesPerSector : 512
PhysicalBytesPerSectorForAtomicity : 4096
PhysicalBytesPerSectorForPerformance : 4096
FileSystemEffectivePhysicalBytesPerSectorForAtomicity : 4096
Выравнивание устройства : Выровнено (0x000)
Выравнивание разделов на устройстве : Выровнено (0x000)
Без штрафа за поиск
Очистка поддерживается
Не поддерживает DAX
Без тонкой подготовки
На нормальном такие:
C:\Windows\system32>fsutil fsinfo sectorinfo E:
LogicalBytesPerSector : 512
PhysicalBytesPerSectorForAtomicity : 512
PhysicalBytesPerSectorForPerformance : 512
FileSystemEffectivePhysicalBytesPerSectorForAtomicity : 512
Выравнивание устройства : Выровнено (0x000)
Выравнивание разделов на устройстве : Выровнено (0x000)
Без штрафа за поиск
Очистка поддерживается
Не поддерживает DAX
Без тонкой подготовки
Вот собственно и вся разница) попытался форматированием диска Е на сбойном привести размеры соответствие - не вышло, форматированием не решается. Пишут, что особенности используемых дисков.
Сейчас все зеркалирования отключены.
Также добавлю, что, судя по виндовым счетчикам производительности, большой нагрузки на дисковую подсистему нет. Утилизация дисков минимальна, лишь в редкие моменты подскакивает до больших значений.
TempDB MSSQL и ЖР 1С выведены на отдельный, от файлов БД и ЖТР, диск, более быстрый.
Нагрузка по ЦПУ и ОЗУ (MSSQL отъедает выделенную ему память) также в норме.
Уважаемое сообщество, подскажите, куда ещё можно копнуть?
23.09.25
✎
11:41
Пусть программист сделает замер производительности и поймёт, куда тратится время.
Может там лишних циклов понакрутили...
Может там лишних циклов понакрутили...
23.09.25
✎
12:13
Здравствуйте. Сегодня провели замер производительности через платформу, на сбойном сервере проверочный отчет показывает общее время выполнения 450 сек (7.5. минуты), а на деле он выполняется не меньше 1200сек (20 минут), что мы фактически наблюдаем при запуске из клиента.
Чем может заниматься платформа всё неучтённое в замере производительности время?))
При этом на тестовом и эталонном серверах этот же отчет формируется за 151 и 150 сек соответственно, что, в принципе, нормальный результат.
Опять же, наблюдая за нагрузкой скуля (через монитор активности) во время замеров, ожидающий процессов и блокировок не насмотрено((
Может быть существуют какие-либо параметры технического журнала 1С, которые можно включить и сбор и уже на них обратить внимание?
Чем может заниматься платформа всё неучтённое в замере производительности время?))
При этом на тестовом и эталонном серверах этот же отчет формируется за 151 и 150 сек соответственно, что, в принципе, нормальный результат.
Опять же, наблюдая за нагрузкой скуля (через монитор активности) во время замеров, ожидающий процессов и блокировок не насмотрено((
Может быть существуют какие-либо параметры технического журнала 1С, которые можно включить и сбор и уже на них обратить внимание?
23.09.25
✎
12:28
150 секунд - это ненормальный результат, это охереть как долго. Я бы закрыл этот отчет и никогда не использовал, проклянув программистов и пользуя свой запрос в консоли, что я и так делаю, вместо ущербных типовых отчетов от 1С
23.09.25
✎
12:30
А по теме - надо смотреть, что там за запрос в отчете, вдруг там через точку к ЛюбаяСсылка и mssql охеревает от левых соединений с десятками тысяч таблиц и сваливает все через lazy table spool. Соберите estimated xml plan и все станет понятно
гуру
23.09.25
✎
12:30
(2) запустите из отладки и сравните объем передаваемых данных. а также проверьте, процессор сервера находится в режиме performance, а не balanced
гуру
23.09.25
✎
12:32
(3) ну заменить на хранение консолидированных данных в РС и расчет регламентом конечно, просится, но вообще, почему нет? сотрудникам ЗП идет, все в плюсе.
гуру
23.09.25
✎
12:45
(4) > Соберите estimated xml plan и все станет понятно
ну типа в (0) про реорганизации и переиндексации написано, которые в т.ч. статистику обновляют, ЕМНИП.
да и по дефолту авторасчет статистики уже давно включен
ну типа в (0) про реорганизации и переиндексации написано, которые в т.ч. статистику обновляют, ЕМНИП.
да и по дефолту авторасчет статистики уже давно включен
23.09.25
✎
12:43
(6) Здравствуйте. Что касается режима работы процессора, Вы же об этом: GUID схемы питания: 4d166729-9479-47d6-9722-f936d0c805f1 (Максимальная производительность) ?
23.09.25
✎
13:06
(4) Здравствуйте. Насколько мне известно, именно в том отчете, который мы берем как мерило теста, таких ссылок нет. Но даже если и есть, то на другом (эталонном) сервере всё выполняется за вменяемое время.
Помимо данного отчета, тормоза проявляются и в регламентных заданиях, типа перепроведения документов (регламентное задание), а это типовая операция.
Что касается "Соберите estimated xml plan и все станет понятно" посмотрю в эту сторону, спасибо за наводку.
Помимо данного отчета, тормоза проявляются и в регламентных заданиях, типа перепроведения документов (регламентное задание), а это типовая операция.
Что касается "Соберите estimated xml plan и все станет понятно" посмотрю в эту сторону, спасибо за наводку.
23.09.25
✎
12:49
(7) Да, автообновление статистики включено + идет обновление её два раза в день со сбросом процедурного кэша.
23.09.25
✎
12:54
(0) Что у вас с распараллеливанием выполнения запросов в настройках серверов СУБД? Одинаковые настройки?
23.09.25
✎
13:07
(11) Здравствуйте. Да, настройки MSSQL впринципе одинаковые, вплоть до расположения файлов системных БД и темпдб, ну и пользовательских, разумеется.
Если вы про параметр "Максимальная степень параллелизма", то он выставлен в 1 (как на ИТС и большинстве статей\форумов пишут)
Если вы про параметр "Максимальная степень параллелизма", то он выставлен в 1 (как на ИТС и большинстве статей\форумов пишут)
23.09.25
✎
13:12
Покажите отчёт: запрос и код обработки данных
23.09.25
✎
13:27
(13) По ссылке код отчета и сам отчет: https://lkz51-my.sharepoint.com/:f:/g/personal/ian_nordciti_ru/ElMFw4SeYqRNoQTxWb_13esBZn6CspuRlN4vcEWFN3JvOA?e=mrAQmM
23.09.25
✎
13:34
(14) Запрос громоздкий и тормозной. Нужно оптимизировать. Админу тут делать нечего
23.09.25
✎
13:42
ВТ_ГрафикиДействующиеСУчетомПериодичности.ГруппаНоменклатуры = ВТ_ДоступнаяНоменклатураСклад.Папка.Родитель.Родитель.Родитель.Родитель.Родитель.Родитель.Родитель.Родитель.Родитель
https://vk.com/video-181251284_456240764
https://vk.com/video-181251284_456240764
23.09.25
✎
13:44
(15) Коллега-программист такое же мнение выразил. Но видите какая ситуация, ясное дело, что запрос не оптимизирован, но ранее он хоть выполнялся за вменяемое время, да и на эталонном сервере он продолжает нормально работать. А из изменений, которые были применены к БД был перевод на полную модель (что как бы маст хэв) и включение зеркалирования (что я в первом сообщении в теме расписал)
После обнаружения тормозов всё вернул на место и, более того, даже проверил с откатом на версию платформы 8.3.27.1508 (на которой тормозов не замечалось) - без толку. Что данный отчет, что регламенты - выполнение стремится к бесконечности.
Временно принято решение мигрировать БД на сервер, где они нормально работает, но хотелось бы понять изначальную причину возникновения тормозов.
Может подскажите, какие параметры в ТЖ 1С стоит указать и обратить на них внимание? На данный момент собираю небольшой ТЖ с такими параметрами:
<?xml version="1.0"?>
<config xmlns="http://v8.1c.ru/v8/tech-log
<log location="F:\1C_logs\err" history="48">
<event>
<eq property="name" value="ATTN"/>
</event>
<event>
<eq property="name" value="ADMIN"/>
</event>
<event>
<eq property="name" value="PROC"/>
</event>
<event>
<eq property="name" value="QERR"/>
</event>
<event>
<eq property="name" value="EXCP"/>
</event>
<event>
<eq property="name" value="EXCPCNTX"/>
</event>
<event>
<eq property="name" value="CLSTR"/>
</event>
<event>
<eq property="name" value="TLOCK"/>
<ne property="WaitConnections" value=""/>
</event>
<event>
<eq property="name" value="CALL"/>
<ne property="RetExcp" value=""/>
</event>
<property name="all"/>
</log>
<log location="F:\1C_logs\ScriptCircRefs" history="48">
<event>
<eq property="Name" value="SCRIPTCIRCREFS"/>
</event>
<property name="All"/>
</log>
<log history="72" location="F:\1C_logs\locks_sql">
<event>
<eq property="Name" value="DBMSSQL"/>
<eq property="p:processName" value="erp"/>
</event>
<property name="t:computerName"/>
<property name="t:connectID"/>
<property name="Context"/>
<property name="Sql"/>
<property name="Sdbl"/>
<property name="lkaid"/>
<property name="lka"/>
<property name="lkp"/>
<property name="lkpid"/>
<property name="lksrc"/>
<property name="tableName"/>
<property name="Usr"/>
<property name="dbpid"/>
</log>
<dbmslocks/>
<scriptcircrefs/>
</config>
После обнаружения тормозов всё вернул на место и, более того, даже проверил с откатом на версию платформы 8.3.27.1508 (на которой тормозов не замечалось) - без толку. Что данный отчет, что регламенты - выполнение стремится к бесконечности.
Временно принято решение мигрировать БД на сервер, где они нормально работает, но хотелось бы понять изначальную причину возникновения тормозов.
Может подскажите, какие параметры в ТЖ 1С стоит указать и обратить на них внимание? На данный момент собираю небольшой ТЖ с такими параметрами:
Подробности
<?xml version="1.0"?>
<config xmlns="http://v8.1c.ru/v8/tech-log
<log location="F:\1C_logs\err" history="48">
<event>
<eq property="name" value="ATTN"/>
</event>
<event>
<eq property="name" value="ADMIN"/>
</event>
<event>
<eq property="name" value="PROC"/>
</event>
<event>
<eq property="name" value="QERR"/>
</event>
<event>
<eq property="name" value="EXCP"/>
</event>
<event>
<eq property="name" value="EXCPCNTX"/>
</event>
<event>
<eq property="name" value="CLSTR"/>
</event>
<event>
<eq property="name" value="TLOCK"/>
<ne property="WaitConnections" value=""/>
</event>
<event>
<eq property="name" value="CALL"/>
<ne property="RetExcp" value=""/>
</event>
<property name="all"/>
</log>
<log location="F:\1C_logs\ScriptCircRefs" history="48">
<event>
<eq property="Name" value="SCRIPTCIRCREFS"/>
</event>
<property name="All"/>
</log>
<log history="72" location="F:\1C_logs\locks_sql">
<event>
<eq property="Name" value="DBMSSQL"/>
<eq property="p:processName" value="erp"/>
</event>
<property name="t:computerName"/>
<property name="t:connectID"/>
<property name="Context"/>
<property name="Sql"/>
<property name="Sdbl"/>
<property name="lkaid"/>
<property name="lka"/>
<property name="lkp"/>
<property name="lkpid"/>
<property name="lksrc"/>
<property name="tableName"/>
<property name="Usr"/>
<property name="dbpid"/>
</log>
<dbmslocks/>
<scriptcircrefs/>
</config>
23.09.25
✎
13:44
Проблема только с отчетом?
Это пять:
ИЛИ ВТ_ГрафикиДействующиеСУчетомПериодичности.ГруппаНоменклатуры = ВТ_ДоступнаяНоменклатураСклад.Папка.Родитель.Родитель.Родитель.Родитель.Родитель.Родитель.Родитель.Родитель
ИЛИ ВТ_ГрафикиДействующиеСУчетомПериодичности.ГруппаНоменклатуры = ВТ_ДоступнаяНоменклатураСклад.Папка.Родитель.Родитель.Родитель.Родитель.Родитель.Родитель.Родитель.Родитель.Родитель
Это пять:
ИЛИ ВТ_ГрафикиДействующиеСУчетомПериодичности.ГруппаНоменклатуры = ВТ_ДоступнаяНоменклатураСклад.Папка.Родитель.Родитель.Родитель.Родитель.Родитель.Родитель.Родитель.Родитель
ИЛИ ВТ_ГрафикиДействующиеСУчетомПериодичности.ГруппаНоменклатуры = ВТ_ДоступнаяНоменклатураСклад.Папка.Родитель.Родитель.Родитель.Родитель.Родитель.Родитель.Родитель.Родитель.Родитель
23.09.25
✎
13:45
(17) Запрос надо переделывать, вдумчиво. Побольше временных таблиц, поменьше соединений и обращений через кучу точек. Убрать эти "января", "февраля". Можно ещё убрать РАЗРЕШЕННЫЕ и выполнять запрос в привилегированном режиме.
23.09.25
✎
13:45
(18) Здравствуйте. Нет, проблема не только с данным отчетом. Его используем просто как пример, мерило "производительности". Т.к., одновременно с началом тормозов, он тоже перестал выполняться за вменяемое время.
23.09.25
✎
13:46
(19) Спасибо за развёрнутое мнение, передам коллегам.
23.09.25
✎
13:46
(20) Такой запрос нельзя считать "мерилом". Это говнокод.
23.09.25
✎
13:56
(22) Если отойти от именно этого примера отчёта, в какие метрики стоит залезть ещё?
Потому как, повторюсь, другой север с аналогичным набором параметров переваривает всё, как должное, благо запас мощности достаточный.
Ради ускорения работы данной ИБ даже ушли от виртуализации на полный bare metal-сервера.
Но, по какой-то причине, на нормальном сервере, где эта БД крутилась 3 месяца без проблем, начали появляться большие задержки.
Потому как, повторюсь, другой север с аналогичным набором параметров переваривает всё, как должное, благо запас мощности достаточный.
Ради ускорения работы данной ИБ даже ушли от виртуализации на полный bare metal-сервера.
Но, по какой-то причине, на нормальном сервере, где эта БД крутилась 3 месяца без проблем, начали появляться большие задержки.
23.09.25
✎
13:57
(23) Я слышал про некий тест Гилёва, который считается эталонным. Прогоните его
http://www.gilev.ru/tpc1cgilv/
http://www.gilev.ru/tpc1cgilv/
23.09.25
✎
14:01
(24) им прогонял, когда на физический сервер приземлял БД) тест был в фиолетовой зоне. Количество попугаев уже не помню.
Но перетестировать никогда не лишнее, спасибо за идею
Но перетестировать никогда не лишнее, спасибо за идею
23.09.25
✎
14:11
(25) Гилёв пишет, что на физическом сервере можно ещё настройками BIOS подшаманить.
http://www.gilev.ru/?s=bios&submit=Найти
http://www.gilev.ru/?s=bios&submit=Найти
23.09.25
✎
14:52
Gemini говорит что дело в диске
### Разбивка вопроса на факты:
1. **Проблема:** Медленное выполнение отчетов и операций, а также длительная отработка регламентов (например, "Групповое перепроведение ИПЧ") в 1С.
2. **Масштаб проблемы:** Затронута одна большая БД (150Гб+) и её "демо" копия на том же сервере. Другие БД на том же сервере работают нормально.
3. **Хронология:** Проблема совпала с переключением модели восстановления БД в "полную", включением обрезки ЖТР MSSQL и настройкой зеркалирования.
4. **Среда:**
* ОС: Windows Server 2022
* СУБД: MS SQL 2022 Enterprise
* Платформа 1С: 8.3.27.1688
* Конфигурация 1С: УНФ 8. Управление предприятием общепита, редакция 3.0 (3.0.5.184)
5. **Попытки решения (неудачные):**
* Пауза/отключение зеркалирования.
* Перезапуски платформы, СУБД, сервера.
* Очистка сеансового кеша 1С.
* Отключение других БД и регламентов.
* Восстановление БД на другом сервере (работает быстро), затем бэкап/восстановление обратно на проблемный сервер (снова медленно).
* Возврат модели восстановления на "простую".
6. **Успешное тестирование:** При восстановлении проблемной БД на *другом* сервере (ранее зеркальном), производительность нормальная (1-1.5 мин против 20-25 мин).
7. **Настройки СУБД:**
* Регламенты по реорганизации/перестроению индексов (фрагментация >5% / >30%).
* Обновление статистики 2 раза в день.
* Очистка процедурного кеша.
8. **Логи MSSQL:** Появление сообщений "There have been 60160 misaligned log IOs which required falling back to synchronous IO." после настройки зеркалирования другой БД на этот же сервер.
9. **Параметры дисков (fsutil fsinfo sectorinfo):**
* **Проблемный сервер:** `PhysicalBytesPerSectorForAtomicity: 4096`, `PhysicalBytesPerSectorForPerformance: 4096`, `FileSystemEffectivePhysicalBytesPerSectorForAtomicity: 4096`.
* **Нормальный сервер:** `PhysicalBytesPerSectorForAtomicity: 512`, `PhysicalBytesPerSectorForPerformance: 512`, `FileSystemEffectivePhysicalBytesPerSectorForAtomicity: 512`.
* Разница в размере кластера диска с БД и ЖТР на основном и зеркальном серверах (NVME SSD). Попытки форматирования на проблемном диске не изменили параметры.
10. **Текущее состояние:** Зеркалирования отключены.
11. **Мониторинг производительности:** Windows-счетчики показывают низкую утилизацию дисков, CPU и RAM в норме (MSSQL потребляет выделенную память).
12. **Размещение файлов:** TempDB MSSQL и ЖР 1С вынесены на отдельный, более быстрый диск.
### Проверка ответа на соответствие каждому факту:
На основе предоставленных фактов, самая явная и критичная проблема, которая **точно** объясняет наблюдаемые симптомы, связана с параметрами дисковой подсистемы и сообщениями об `misaligned log IOs`.
**Основная гипотеза:** Проблема связана с неоптимальной конфигурацией дисковой подсистемы на "проблемном" сервере, в частности, с несоответствием размера сектора, что приводит к штрафам производительности при записи логов и данных.
**Развернутый ответ и куда копать:**
#### 1. Диагностика проблемы с `misaligned log IOs` и размером сектора (Оценка: 10/10)
Это сообщение в логах SQL Server: "There have been **misaligned log IOs** which required falling back to **synchronous IO**" является **ключевым**. Оно прямо указывает на то, что SQL Server обнаруживает несовпадение между размером сектора, который он "ожидает" (обычно 512 байт, но современный SQL Server хорошо работает с 4k секторами при правильной конфигурации), и тем, как диск сообщает о своих физических секторах (Advanced Format disks).
* **Ваши `fsutil` данные это подтверждают:**
* На проблемном сервере: `PhysicalBytesPerSectorForAtomicity : 4096`, `PhysicalBytesPerSectorForPerformance : 4096`. Это означает, что диск физически оперирует 4КБ секторами.
* На нормальном сервере: `PhysicalBytesPerSectorForAtomicity : 512`, `PhysicalBytesPerSectorForPerformance : 512`. Это означает, что диск эмулирует 512-байтные сектора.
* **Почему это проблема:** Когда SQL Server пытается записать данные или лог-файлы блоками, которые не совпадают с физическим размером сектора диска (например, пишет 512 байт на 4КБ сектор), операционной системе и диску приходится выполнять дополнительную работу: читать весь 4КБ сектор, изменять часть 512 байт, а затем записывать весь 4КБ сектор обратно. Это называется "Read-Modify-Write" цикл и **резко снижает производительность ввода-вывода**, особенно для лог-файлов, которые являются критически важными для производительности транзакций и операций записи. Сообщение "falling back to synchronous IO" означает, что вместо асинхронных, более быстрых операций, SQL Server вынужден ждать завершения каждой операции записи, что еще больше замедляет работу.
* **Почему на другом сервере все ок:** Другой сервер, несмотря на то, что у него NVME, каким-то образом (возможно, через драйвер диска, прошивку или настройки контроллера) представляет себя операционной системе как диск с 512-байтными секторами, или же на нем настроена правильная конфигурация для 4КБ секторов, которая не вызывает `misaligned IOs`.
* **Почему это проявилось при переходе на полную модель восстановления и зеркалировании:**
* **Полная модель восстановления:** Увеличивает объем записей в журнал транзакций (ЖТР), так как все изменения фиксируются для возможности восстановления на момент времени. Это увеличивает нагрузку на дисковую подсистему ЖТР.
* **Зеркалирование:** Также увеличивает нагрузку на ЖТР, так как транзакции должны быть отправлены на зеркало.
* По сути, эти изменения увеличили объем дисковых операций, что обнажило проблему с `misaligned IOs`, которая, возможно, существовала и раньше, но не была столь критичной.
**Рекомендации по этому пункту:**
1. **Подтверждение выравнивания:** Используйте `DISKPART` и команду `list partition` затем `select partition X` и `detail partition` для проверки смещения (Offset) разделов. Для 4K секторов смещение должно быть кратно 4096 байтам (например, 1024 KB = 1048576 байт, что кратно 4096).
2. **Переформатирование:** Если разделы выровнены неправильно, или если системные утилиты не могут корректно работать с 4K секторами, **единственное надежное решение – это пересоздание разделов и переформатирование диска с правильным выравниванием**. Вы сказали, что форматирование не помогло изменить `fsutil` данные, но это не значит, что выравнивание было сделано правильно. Возможно, проблема глубже, на уровне драйверов диска или контроллера.
* **Внимание:** Это разрушительная операция. Требуется полный бэкап данных.
* При создании разделов убедитесь, что смещение (offset) кратно 4096 байтам (например, 1MB или 8MB). Современные ОС обычно делают это автоматически, но стоит перепроверить.
3. **Обновление драйверов/прошивок:** Проверьте наличие обновлений для драйверов контроллера диска (RAID-контроллера, если есть) и прошивки самих NVME SSD. Производители могут выпускать исправления для проблем с 4K секторами.
4. **Проверка настроек SQL Server:** Убедитесь, что SQL Server установлен на диск, который правильно выровнен. Для SQL Server 2022 это уже не такая частая проблема, как для старых версий, но все же стоит проверить.
5. **Trace Flag 1800 и 1802:** В некоторых случаях (особенно для старых SQL Server или специфических конфигураций) могли помочь Trace Flags 1800 и 1802, которые принуждают SQL Server использовать определенный размер сектора. Однако для SQL Server 2022 это менее вероятно и может привести к другим проблемам, если диск на самом деле не поддерживает этот размер. Лучше решить проблему на уровне ОС/диска.
#### 2. Диагностика производительности 1С и SQL Server (Оценка: 8/10)
Несмотря на то, что проблема с дисками является наиболее вероятной, стоит также рассмотреть другие аспекты, которые могли быть затронуты.
* **Планы запросов:**
* На проблемном сервере, после того как вы восстановили БД, SQL Server мог построить неоптимальные планы запросов из-за изменившейся производительности дисковой подсистемы.
* Даже при наличии регламентов по перестроению индексов и обновлению статистики, "медленные" диски могут влиять на выбор планов.
* **Что делать:** Используйте SQL Server Management Studio (SSMS) для анализа самых медленных запросов 1С. Запустите проблемный отчет и посмотрите, какие запросы выполняются долго. Анализируйте их планы выполнения (Execution Plan) на предмет дорогих операций (например, Table Scan, Key Lookup, Bookmark Lookup) и больших объемов чтения данных.
* **Extended Events / Profiler:** Настройте сбор событий SQL Server (например, `sql_statement_completed`, `rpc_completed`) для выявления самых медленных запросов, их длительности и CPU/IO.
* **Блокировки и взаимоблокировки (Deadlocks):**
* Замедление операций ввода-вывода может увеличить время удержания блокировок, что, в свою очередь, может привести к увеличению блокировок и взаимоблокировок между сеансами 1С.
* **Что делать:** Проверяйте логи SQL Server на наличие сообщений о блокировках. Используйте `sp_whoisactive` или другие инструменты для мониторинга активных блокировок во время выполнения медленных операций.
* **Особенности 1С:УНФ и "Групповое перепроведение ИПЧ":**
* Этот регламент может быть очень ресурсоемким, особенно на больших базах, так как он пересчитывает взаиморасчеты, себестоимость и другие зависимые данные.
* **Что делать:**
* Проанализируйте, какие именно операции внутри регламента занимают больше всего времени. Возможно, есть конкретные документы или регистры, которые обрабатываются особенно долго.
* Возможно, после восстановления на проблемном сервере, состояние данных или индексов стало таким, что этот регламент стал работать медленнее. Стоит сравнить состояние индексов (фрагментацию, статистику) на "нормальном" и "проблемном" серверах.
* **Параметры запуска 1С-сервера (ras, rphost):**
* Количество рабочих процессов, объем памяти на процесс. Хотя вы указали, что ОЗУ в норме, иногда неоптимальные настройки могут влиять на производительность.
* **Что делать:** Проверить настройки кластера серверов 1С.
* **Индексы и статистика:**
* Вы упомянули регламенты по реорганизации/перестроению индексов и обновлению статистики. Это хорошо. Убедитесь, что они действительно эффективно работают и охватывают все необходимые индексы/таблицы.
* **Что делать:** Проверьте актуальность статистики (`DBCC SHOW_STATISTICS`) для крупных таблиц и индексов, участвующих в медленных запросах.
#### 3. Мониторинг производительности (Оценка: 9/10)
Вы указали, что Windows-счетчики показывают низкую утилизацию дисков. Это может быть обманчиво:
* **Низкая утилизация ≠ высокая производительность:** Если диск выполняет операции Read-Modify-Write, он может быть "занят" на низкий процент, но каждая операция будет занимать гораздо больше времени, чем должна. Это проявляется в высоких значениях `Avg. Disk sec/Transfer` (среднее время на передачу) или `Disk Queue Length` (длина очереди диска), даже при низком `Disk % Utilization`.
* **Что делать:**
* Отслеживайте счетчики производительности диска более детально:
* `PhysicalDisk\Avg. Disk sec/Read`
* `PhysicalDisk\Avg. Disk sec/Write`
* `PhysicalDisk\Current Disk Queue Length`
* `PhysicalDisk\Disk Bytes/sec`
* `PhysicalDisk\Disk Transfers/sec`
* Сравните эти показатели на "нормальном" и "проблемном" серверах во время выполнения одного и того же отчета. Вы, скорее всего, увидите значительно более высокие значения `Avg. Disk sec/Read` и `Avg. Disk sec/Write` на проблемном сервере.
* Используйте утилиты типа `Perfmon` или `Resource Monitor` для детального анализа.
#### 4. Прочие факторы (Оценка: 7/10)
* **Антивирусное ПО:** Убедитесь, что папки с файлами БД, логов и TempDB исключены из сканирования антивирусом. Антивирус может значительно замедлять операции ввода-вывода.
* **Энергосбережение:** Проверьте настройки электропитания на сервере. Они должны быть установлены в режим "Высокая производительность" (High Performance).
* **Обновления ОС/SQL Server:** Убедитесь, что установлены все последние обновления для Windows Server 2022 и SQL Server 2022. Иногда исправления производительности могут быть в кумулятивных обновлениях.
* **BIOS/UEFI:** В некоторых случаях настройки BIOS/UEFI (например, режим работы контроллера диска - AHCI vs RAID, настройки кэша) могут влиять на производительность NVME.
### Заключение:
Наиболее вероятная причина ваших проблем – это **misaligned log IOs** из-за несовпадения логического и физического размера сектора на дисках проблемного сервера. Это фундаментальная проблема дисковой подсистемы, которая будет влиять на все операции ввода-вывода, особенно на запись в журнал транзакций, что критично для 1С.
**Мой совет:** Сосредоточьтесь в первую очередь на диагностике и решении проблемы с дисками (пункт 1). Если это не поможет, или поможет частично, тогда переходите к детальной диагностике SQL Server и 1С (пункт 2), а также внимательному мониторингу (пункт 3).
Неудача с "финтом" бэкапа/развертки подтверждает, что проблема не в данных самой БД, а в окружении, в котором она работает на проблемном сервере. И разница в `fsutil` данных, а также сообщения в логах MSSQL, указывают прямо на диск.
23.09.25
✎
16:01
(27) Здравствуйте. Я тож с нейронкой, правда ChatGPT, консультировался)
Изначально и копал в сторону дисков, но, после настройки мониторинга виндовых метрик по дискам, понял, что тамм нет особенно нагрузки, а такое секторное разбиение так пагубно влиять не должно. Да и ведь работало оно 3 месяца без нареканий)
И, если говорить об ошибке "misaligned log IOs", то, после отключения зеркалирования базы с эталонного сервера, она пропала из логов.
Я ещё более внимательно Ваш ответ прочитаю, может получится ещё что-то попробовать
Изначально и копал в сторону дисков, но, после настройки мониторинга виндовых метрик по дискам, понял, что тамм нет особенно нагрузки, а такое секторное разбиение так пагубно влиять не должно. Да и ведь работало оно 3 месяца без нареканий)
И, если говорить об ошибке "misaligned log IOs", то, после отключения зеркалирования базы с эталонного сервера, она пропала из логов.
Я ещё более внимательно Ваш ответ прочитаю, может получится ещё что-то попробовать
23.09.25
✎
16:04
(26) в биос доступа нет, так как сервер находится в дц Selectel, но при взятии его в аренду просили ТП настроить в соответствии с требованиями для работы с 1С.
В частности с включением буста для процессора AMD Ryzen 9 7950X
В частности с включением буста для процессора AMD Ryzen 9 7950X
23.09.25
✎
16:05
(31) Прогоняешь тест Гилева, получаешь больше 70 попугаев и шлёшь программистов лесом.
23.09.25
✎
17:10
(32) у нас что-то порядка 90 было, кажется.
Пока принято решение перенести тормозящую БД на сервер, где ей ОК. Дальше буду копать в окружении "сбойного" сервера, может найдётся чего, заодно потестирую свежим тестом Гилёва. Хоть и синтетика, но в прошлые разы было весьма показательно.
Если вдруг будут ещё какие-либо мысли, то буду признателен, если поделитесь.
Пока принято решение перенести тормозящую БД на сервер, где ей ОК. Дальше буду копать в окружении "сбойного" сервера, может найдётся чего, заодно потестирую свежим тестом Гилёва. Хоть и синтетика, но в прошлые разы было весьма показательно.
Если вдруг будут ещё какие-либо мысли, то буду признателен, если поделитесь.
23.09.25
✎
18:21
(22) этот говнокод - эталон тормозов.
23.09.25
✎
18:25
(33) попробуй помониторить сервера т.н. "скриптом vde69" (от и тут в базе знаний был, и на нимфостарте). Может, увидишь значимые различия
23.09.25
✎
20:44
На заметку админам:
Программист 1С может затормозить любой сервер своим говнокодом.
Программист 1С может затормозить любой сервер своим говнокодом.
23.09.25
✎
21:07
(36)+ на самом деле любой программист, не только 1С
24.09.25
✎
09:16
(37) справедливо)))
30.09.25
✎
09:33
Всем интересующимся здравствуйте.)
В общем, если подытожить все проведенные эксперименты, проблема скрылась в недостаточном чтении описания параметров ТЖ 1С и их влияния на производительность платформы. %)
Примерно в то же время, когда была включена полная модель БД с зеркалированием, я включил в ТЖ платформы параметр "SCRIPTCIRCREFS", который используется для диагностики использования циклических ссылок при работе встроенного языка, очень уж хотелось мне помочь программистам в оптимизации)
По итогу вышло совсем наоборот.
Судя по описанию на ИТС ( https://dl03.1c.ru/content/Platform/8_3_17_1549/1cv8upd_8_3_17_1549.htm#43092c4b-8b19-11e6-a3f7-0050569f678 ) "Использование данной возможности может негативно сказаться на производительности прикладного решения. Рекомендуется использовать данную возможность только для целей тестирования" и, в данном случае, может = точно негативно скажется на производительности.
После отключение данного параметр из сбора ТЖ отчет забегал как надо, что наводит на мысль, что и прочие функции ИБ будут работать нормально. Сразу после удаления его из параметров ТЖ, в динамике, этого явно не было видно, но после повторного запуска отчета (после удаления параметра) и/или перезапуска процесса платформы эффект был мгновенный.
Радует, что скуль, диски и, в данном случае, код оказались не причем)
Снова сработал тезис "в решении проблемы главное не выйти на самого себя".
Всем спасибо за идеи и помощь.
В общем, если подытожить все проведенные эксперименты, проблема скрылась в недостаточном чтении описания параметров ТЖ 1С и их влияния на производительность платформы. %)
Примерно в то же время, когда была включена полная модель БД с зеркалированием, я включил в ТЖ платформы параметр "SCRIPTCIRCREFS", который используется для диагностики использования циклических ссылок при работе встроенного языка, очень уж хотелось мне помочь программистам в оптимизации)
По итогу вышло совсем наоборот.
Судя по описанию на ИТС ( https://dl03.1c.ru/content/Platform/8_3_17_1549/1cv8upd_8_3_17_1549.htm#43092c4b-8b19-11e6-a3f7-0050569f678 ) "Использование данной возможности может негативно сказаться на производительности прикладного решения. Рекомендуется использовать данную возможность только для целей тестирования" и, в данном случае, может = точно негативно скажется на производительности.
После отключение данного параметр из сбора ТЖ отчет забегал как надо, что наводит на мысль, что и прочие функции ИБ будут работать нормально. Сразу после удаления его из параметров ТЖ, в динамике, этого явно не было видно, но после повторного запуска отчета (после удаления параметра) и/или перезапуска процесса платформы эффект был мгновенный.
Радует, что скуль, диски и, в данном случае, код оказались не причем)
Снова сработал тезис "в решении проблемы главное не выйти на самого себя".
Всем спасибо за идеи и помощь.
30.09.25
✎
09:35
(39) Хм... Решение было на поверхности
30.09.25
✎
09:46
(39) А проверьте ещё параметры журнала регистрации (режим разделения и формат).
Статья в тему: https://habr.com/ru/companies/softpoint/articles/941666/
Статья в тему: https://habr.com/ru/companies/softpoint/articles/941666/
|
30.09.25
✎
12:11
(40) да, всё именно так. К сожалению, бездумно подошел к включению параметра. Когда прочитал про то, что возможно (!) снижение производительности - был обескуражен.
Не думал, что сбор ТЖ хоть как-то влияет на производительность)
Не думал, что сбор ТЖ хоть как-то влияет на производительность)
30.09.25
✎
12:12
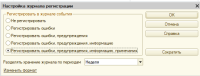
(41) как раз в данной ИБ, где обозначилась проблема, происходит сбор ЖР 1С по предпоследней галке, без "примечаний".
Со статьёй ознакомлюсь, спасибо)
Со статьёй ознакомлюсь, спасибо)
30.09.25
✎
12:29
(41) Проверил. ЖР 1С разделяется по "год" и уже преобразован в новый формат.
Также, когда "проблема" обнаружилась, первым делом порезали ЖР до 3х месяцев и переделали индекс полнотекстового поиска, т.к. до этого он сильно раздулся.
Спасибо за наводку!
Также, когда "проблема" обнаружилась, первым делом порезали ЖР до 3х месяцев и переделали индекс полнотекстового поиска, т.к. до этого он сильно раздулся.
Спасибо за наводку!
30.09.25
✎
13:03
(44) Лучше поставить Неделя
30.09.25
✎
13:15
(14) А вот там - сколько итераций цикла? Думаю, что этот кусок как раз нужно переписывать.
Для Каждого СтрокаГрафики из ДействующиеГрафики Цикл
ДатыГрафика = Обработки.ИПЧ_ЗакупкаТоваров.ПолучитьДатыРазмещенияИОтгрузкиПоДаннымГрафика(СтрокаГрафики, ДатаДокумента, Истина);
СтрокаГрафики.ДатаРазмещения = ДатыГрафика.ДатаРазмещения;
СтрокаГрафики.ДатаПотребности = ДатыГрафика.ДатаПотребности;
КонецЦикла;
Для Каждого СтрокаГрафики из ДействующиеГрафики Цикл
ДатыГрафика = Обработки.ИПЧ_ЗакупкаТоваров.ПолучитьДатыРазмещенияИОтгрузкиПоДаннымГрафика(СтрокаГрафики, ДатаДокумента, Истина);
СтрокаГрафики.ДатаРазмещения = ДатыГрафика.ДатаРазмещения;
СтрокаГрафики.ДатаПотребности = ДатыГрафика.ДатаПотребности;
КонецЦикла;
30.09.25
✎
13:16
(42) Я как-то профайлером SQL подключился к рабочей базе и забыл отключиться. Потом долго понять не могли, почему весь день база тормозит.
30.09.25
✎
15:51
Скажу из личных наблюдений , что 27.1688 как и 27.1719 как и 27.1644, сильно тормознее 27.1606
Увы но факт..
Откатились на проде на 1606, и все стало достаточно заметно получше...
И да факт что 27.1606 тормознее 25.1394 что весьма удручает.
Увы но факт..
Откатились на проде на 1606, и все стало достаточно заметно получше...
И да факт что 27.1606 тормознее 25.1394 что весьма удручает.
30.09.25
✎
16:15
(48) ЗУП 3 при обновлении на платформе 1644 висит больше часа в конфигураторе.
30.09.25
✎
16:17
(49) выше 27.1606 не пригодны для эксплуатации, ждём 28
02.10.25
✎
17:23
(48) Здравствуйте. Ну тут скажу так, что коллеги-программисты гоняли неделю (насколько сильно не могу сказать) версию 27.1688 - было норм, а вот на версии 1644 тормоза заметили.
В Компании 3 нагруженных и 4 практически в холостую работающих сервера (геораспределены, 2 из них виртуальные) и там с платформой 27.1688 каких-то глобальных тормозов не замечено.
В Компании 3 нагруженных и 4 практически в холостую работающих сервера (геораспределены, 2 из них виртуальные) и там с платформой 27.1688 каких-то глобальных тормозов не замечено.
02.10.25
✎
17:24
(46) Здравствуйте. Я программисту показал эту нашу ветку) Сказал, что будут улучшать и оптимизировать код, но насколько скоро, особенно если учесть, что сейчас всё в норме - вопрос открытый.
Спасибо за рекомендацию.
Спасибо за рекомендацию.
02.10.25
✎
17:25
(45) Что касается разделения журнала, почему неделя лучше? На сколько я понимаю, раз используется новый формат журналирования платформы, то время разделения не особенно существенно.
Или, в зависимости от разделения, файлы *.lgp будут меньшего объема?
Или, в зависимости от разделения, файлы *.lgp будут меньшего объема?
02.10.25
✎
17:31
(53) Да, журнал получается более управляемый с точки зрения администрирования. Старые файлы можно перемещать на другие диски
02.10.25
✎
17:40
(54) А если нужно будет просмотреть журнал из разделенного файла, который перемещен, то достаточно будет его подкинуть обратно?
02.10.25
✎
18:02
(55) смотреть на копии
03.10.25
✎
09:06
А, понял. принял)
Ещё раз спасибо за ликбез!
Ещё раз спасибо за ликбез!
