| 1C |
| 1С v8 |
25.12.24
✎
06:32
Приветствую всех! Скажите, существует ли какое то решение в виде компоненты или библиотеки которые позволят считывать из загруженного pdf файла картинки штрихкодов и выводить их значение в виде строки. Спасибо заранее :)
25.12.24
✎
06:58
У 1С есть целый сервис распознавания документов
25.12.24
✎
07:00
Можно в какую-нибудь нейроночку кидать, они тоже с таким справляются. Кажется, Низамов у себя в ютубчике показывал, как что-то такое на коленке собрать.
25.12.24
✎
07:15
Pyzbar
ZXing
ZXing.net
Google Vision API
AWS Rekognition
Zebra Crossing (ZXing) REST API
Dynamsoft Barcode Reader
ZXing
ZXing.net
Google Vision API
AWS Rekognition
Zebra Crossing (ZXing) REST API
Dynamsoft Barcode Reader
25.12.24
✎
07:18
(3) да я в гитхабе их и нашел, и похоже что бы их использовать придется свою библиотеку делать... Google Vision API вроде ничего.
25.12.24
✎
07:34
Barcode4J
25.12.24
✎
07:35
(4) кого - их?
25.12.24
✎
07:59
(0) Вас ждет дорога приключений.
25.12.24
✎
08:08
(7) я уж понял как только в инет полез искать инфу)))
25.12.24
✎
08:09
(6) сервисы типа ZXing
25.12.24
✎
08:10
25.12.24
✎
08:13
(9) то есть вы выбираете Zxing rest api?
25.12.24
✎
08:33
(0)имэйдж мейджик + зебар. Но вначале в картинку(пнг) из пдф с помощью чего-то что использует кайро.
25.12.24
✎
09:00
(11) пока изучаю все) спасибо всем за советы))
гуру
25.12.24
✎
09:17
Немного не в тему, топик-стартеру, как я понял, нужно решение для постоянной работы, что-бы это автоматом работало из 1С, и ШК, как я понял, линейные... Но, на ИнфоСтарте было решение, под похожую задачу: https://infostart.ru/1c/tools/1310318/
Правда, там не совсем автоматом это все делается - сначала одной обработкой из PDFки выдергиваются картинки ШК DM в отдельные файлы JPEG, а потом, они распознаются, и получается текстовый файл с содержимым ШК DM.
Посмотрите, может поможет и натолкнет на путь решения Вашей задачи.
PS Мне в свое время, эта публикация очень помогла - когда была "акция по маркировки "левых остатков тапочек и шмоток" в рознице", клиенты массово заказывали ШК марок в ЧЗ... Но, бестолковость не позволяла сохранять их сразу в csv - "типа, че это такое непонятное - ???", сохраняли в PDF (ну, типа а чего не так, готовые марки!), а там формат, ну мягко говоря "не для удобной печати на наклейки"... А второй раз скачать уже полученные ШК в текст - ЧЗ не давал...
Говорят - "надо напечатать!" А как? Их тысячи... В ручную не переформатировать. Эти обработки очень помогли, после них, у меня были файлы текстовые с марками, а уж напечатать наклейки по ним - дело техники, там-же на ИнфоСтарте есть моя обработка для этого :-)
PSS А вообще, конечно надо задачу смотреть - если это разово, то можно воспользоваться решением с ИнфоСтарта с минимальными доработками, а если действительно нужно "на постоянку", то проще избавиться от такого гимороя - поставить вопрос, что-бы документы присылали в ЭДО с нормальными ШК строкой, а не картинки распознавать.
Правда, там не совсем автоматом это все делается - сначала одной обработкой из PDFки выдергиваются картинки ШК DM в отдельные файлы JPEG, а потом, они распознаются, и получается текстовый файл с содержимым ШК DM.
Посмотрите, может поможет и натолкнет на путь решения Вашей задачи.
PS Мне в свое время, эта публикация очень помогла - когда была "акция по маркировки "левых остатков тапочек и шмоток" в рознице", клиенты массово заказывали ШК марок в ЧЗ... Но, бестолковость не позволяла сохранять их сразу в csv - "типа, че это такое непонятное - ???", сохраняли в PDF (ну, типа а чего не так, готовые марки!), а там формат, ну мягко говоря "не для удобной печати на наклейки"... А второй раз скачать уже полученные ШК в текст - ЧЗ не давал...
Говорят - "надо напечатать!" А как? Их тысячи... В ручную не переформатировать. Эти обработки очень помогли, после них, у меня были файлы текстовые с марками, а уж напечатать наклейки по ним - дело техники, там-же на ИнфоСтарте есть моя обработка для этого :-)
PSS А вообще, конечно надо задачу смотреть - если это разово, то можно воспользоваться решением с ИнфоСтарта с минимальными доработками, а если действительно нужно "на постоянку", то проще избавиться от такого гимороя - поставить вопрос, что-бы документы присылали в ЭДО с нормальными ШК строкой, а не картинки распознавать.
гуру
25.12.24
✎
09:24
(0) хехе, какие интересные темы всплывают
"github.com/makiuchi-d/gozxing"
"github.com/sunshineplan/imgconv"
"github.com/sunshineplan/pdf"
"github.com/makiuchi-d/gozxing"
"github.com/sunshineplan/imgconv"
"github.com/sunshineplan/pdf"
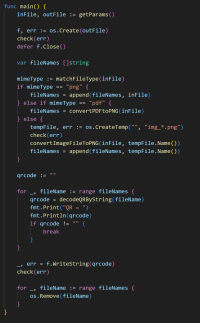
|
гуру
25.12.24
✎
09:27
(15)+ суть преобразовываем pdf в картинки png
затем через gozxing (порт либы zxing на go) распознаем ШК
работает замечательно пока качество хорошее, например чеки с электронных магазинов сразу в pdf
на реальных же сканах хренового качества с выцветших чековых лент - все плохо
затем через gozxing (порт либы zxing на go) распознаем ШК
работает замечательно пока качество хорошее, например чеки с электронных магазинов сразу в pdf
на реальных же сканах хренового качества с выцветших чековых лент - все плохо
25.12.24
✎
09:28
(14)Может у него потоковое сканирование документов или как там это называется.
25.12.24
✎
09:30
(16)Да при плохом качестве процент распознания тоже плохой.) Может нейронки помогут? Ну так в качестве бреда...
гуру
25.12.24
✎
09:32
(18) ИИ помогут подбирать параметры предобработки картинок
для изменения контрастности и т.д.
и вырезки ШК в отдельные картинки
еще в чб или оттенки серого переводить если цветные и т.д.
короче все сложно и потянет на отдельный подпроект
самое главное откуда обучающую выборку брать
для изменения контрастности и т.д.
и вырезки ШК в отдельные картинки
еще в чб или оттенки серого переводить если цветные и т.д.
короче все сложно и потянет на отдельный подпроект
самое главное откуда обучающую выборку брать
25.12.24
✎
09:42
25.12.24
✎
09:47
(14) у меня именно так и было, менеджеры хреновы. В результате что о качнул с ИС, восьмерочник наш подделал и все получилось. Но тонкости уже не помню.
25.12.24
✎
09:58
Веселые истории экран покажет наш.
Автор, знай, если это ЧестныйЗнак, то там вполне могут быть не картинки.
Автор, знай, если это ЧестныйЗнак, то там вполне могут быть не картинки.
гуру
25.12.24
✎
10:30
(22) если это ЧЗ то лучше как картинки
ибо формат внутри PDF может поменяться в любой момент
а с хорошего качества (не сканов) штрихкоды прекрасно через zxing читаются
ибо формат внутри PDF может поменяться в любой момент
а с хорошего качества (не сканов) штрихкоды прекрасно через zxing читаются
25.12.24
✎
10:37
Матрица Datamatrix может быть набрана квадратиками при помощи языка TrueScript, прямо внутри pdf файла, без всякого хранения картинки.
Ииии, чтобы что-то при этом распознать - pdf нужно отрендерить встроенными pdf-средствами. Живите теперь с этим.
Ииии, чтобы что-то при этом распознать - pdf нужно отрендерить встроенными pdf-средствами. Живите теперь с этим.
25.12.24
✎
10:39
у каждой задачи есть начало. Может и не надо каждую задачу решать в лоб, а стоит уточнить там где этот файл сделали по поводу других форматов?
25.12.24
✎
11:24
(23) все именно таки обстоит.. я теперь в легкой прострации)))
25.12.24
✎
11:25
(24) я пробовал онлайн сервисом парсить pdf файл и он расшифровал эти штрихкоды в текст
25.12.24
✎
11:39
(24) TrueScript нет такого языка
25.12.24
✎
11:43
(19) Примеры в студию
25.12.24
✎
20:00
(15) там же не все портировано
25.12.24
✎
20:30
(28) ошиблись?